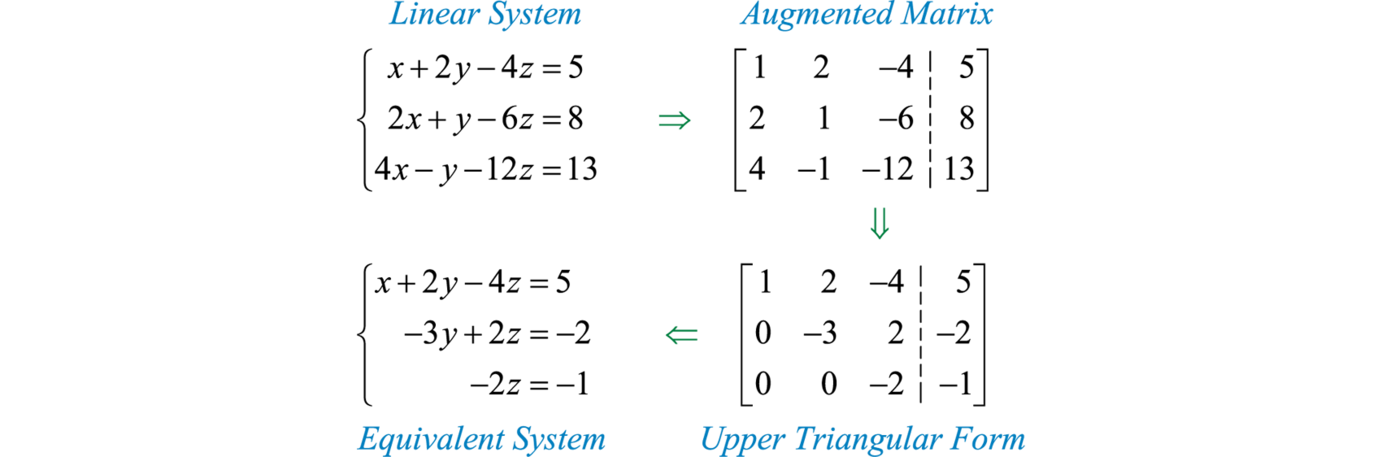
یکی از روش های حل دستگاه n معادله و n مجهول اینه که ماتریس ضرایب رو به شکل مثلثی در بیاریم.
این الگوریتم جوریه که برای صفر کردن درایه های ماتریس، از سطر های بالایی یا پایینی استفاده میکنیم و مضربی از یک سطر را با سطری دیگر جمع میکنیم تا درایه ی مورد نظر صفر شود.
###مشکل
وقتی که این الگوریتم رو پیاده سازی میکنیم، کامپیوتر به ترتیب از بالا به پایین(یا از پایین به بالا) شروع به مثلثی کردن ماتریس ضرایب میکنه، اما این اصلا خوب نیست، و دوتا مشکل داره:
در بعضی جاها کامپیوتر به اعدادی مثل ۱۰/۳ میرسه و مجبور میشه این اعداد رو گرد کنه که این باعث بوجود امدن خطا میشه و این در حالی هست که اگر کامپیوتر از یک سطر دیگه استفاده میکرد، به این عدد نمیرسید. و نیاز به گرد کردن نبود.
گاهی اوقات بعضی سطر ها اعداد بسیار بزرگی دارند که انجام محاسبات روی این اعداد، زمان بیشتری میگیرد و این در حالی است که اگر از سطر های دیگر استفاده کنیم، میتونیم به مناسبت وحود اعداد کوچک تر، محاسبات سریع تری داشته باشیم.
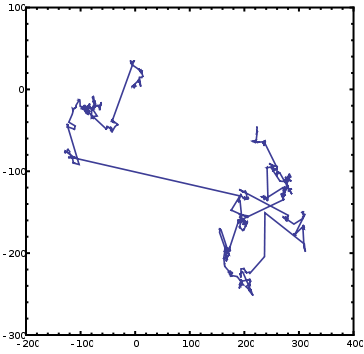
ممکنه بشه به کمک الگوریتم هایی که برای جستجو استفاده میشه، الگوریتم حل معادله رو هم بهینه کرد. الگوریتم هایی که سیستم های طبیعی برای پیدا کردن هدفشون ازش بهره میبرن، از یه حرکت منظم یا جهت دار مشخص پیروی نمیکنه.
###مثال
یه سنجاب برا پیدا کردن غذا، هیچ وقت شروع نمیکنه به حرکت منظم در بین درخت ها با یه ترتیب خاص. بلکه شروع میکنه به صورت تصادفی بین درخت ها سفر کردن. و این حرکت تصادفی هم در ضمن یه حرکت پخشی ساده نیست، بلکه هر از چند گاهی میاد و یه قدم بلند برمیداره به سمت درخت های دورتر. به این گشت سنجاب ها میگن پرواز لوی. و اگه به رد حرکت سنجاب ها نگاه کنیم چیزی مشابه شکل زیر میبینیم:
از چنین الگوریتم هایی برای بهینه کردن موتورهای جستجو هم بهره میبرن.
حالا برگردیم سر سوال مثلثی کردن ماتریس ضرایب، اگه به جا اینکه به کامپیوتر بگیم به ترتیب از بالا به پایین شروع کنه به مثلثی کردن، بهش اجازه بدیم یه کم بگرده تا بهترین سطر رو برای این کار پیدا کنه، مقداری خرج هزینه ی محاسباتی خواهیم داشت برا گشتن، از اون ور مقداری درامد محاسباتی خواهیم داشت به دلیل اینکه مثلثی کردن کمتر طول میکشه.
و احتمالا چنین الگوریتمی فقط برا ماتریس های بزرگتر از یه حدی به صرفه هست که اگه کسی دست به قلم باشه، میتونه با محاسبه به دستش بیاره.
برای کم کردن این مشکل یک ایده به ذهنم رسید:
وقتی که الگوریتم به همچین اعدادی (مثل 10/3) میرسه، سطر های از اون سطر به بعد رو به صورت تصادفی جابجا کنه و دوباره الگوریتم حل رو اجرا کنه تا به احتمالی از این خطا دور بمونیم.
ولی حالا دوتا مشکل داریم:
چجوری دقت این الگوریتم رو با الگوریتم ساده ی قبلی مقایسه کنیم.
چه الگوریتمی لازم داریم تا بتونیم اعدادی مثل 10/3 رو تشخیص بدیم؟ این اعداد جه ویژگی ای دارند که بشه با اون ویژگی به کامپیوتر فهموند که این عدد اعشاریِ نامتنهایی است؟
اگه فرض کنیم در برنامه برا عدد کوچکتر، متغیر کمبیتتری اختصاص میدیم، حجم محاسبات و سرعت برنامه نویسی متفاوت میشه. مثلا اگه عددمون یه عدد صحیح کوچکتر از ۲۵۶ هست، میتونیم از عدد صحیح هشت بیتی استفاده کنیم و اگه کوچکتر از ۶۵۵۳۶، از متغیر ۱۶ بیتی:
Notes
Unique representable values
Size
$2^8$
$256$
$8-bit$
$2^{16}$
$65536$
$16-bit$
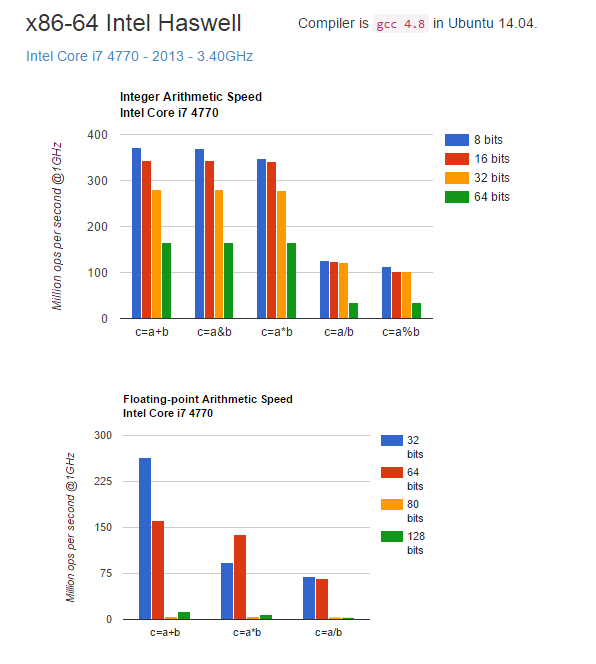
مقایسه ی ساده ای هم بین سرعت انجام محاسبات تکراری در یه cpu اینتل توسط یه مهندس نرم افزار، آقای لیمور، انجام شده که تصویری ازش رو اینجا گذاشتم:
پ.ن. البته همه این حرفا وقتی برقراره که نوع متغیری که به عددها نسبت میدیم متفاوت باشه، وگرنه اگه هر دو عدد کوچک و بزرگ در یه جور متغیر ذخیره بشن، هزینه ی محاسباتی یکیه!