یه سوالی دارم که فکر میکنم با اطلاعات تـئوری نمیتونم جواب قانع کننده بهش بدم. تجربی کارهایی که میشناختم هم نتونستن جواب درستی بهم بدن. فکر کردم اینجا ممکنه بحث های ساده ای برای فهمش بیابم:
فرض کنین یه تابع داریم که در یک بازه ی زمانی محدود اندازه گیری شده، به شکل یه سری زمانی. اگه یکی بیاد ادعا کنه این تابع نویزه و اطللاعاتی نداره، چه جوری این حرف رو میشه تست کرد؟
مسئله اینه که در بعضی آزمایش ها امکان گرفتن داده های زیاد وجود نداره، و در نتیجه تعداد اندازه گیری ها برای اینکه به راحتی به نتیجه اعتماد کنی وجود نداره. مثلا بعضی ازمایش های بیولوژی چنین وضعیتی دارن.
معمولا خودهمبستگی یه تابع در چنین وقت هایی مفیده، ولی وقتی تابع در یه بازه ی محدود تعریف شده باشه، این پارامتر نمیتونه محک خوبی باشه، در واقع بدیهیه که دلتا نمیده هیچ وقت.
فکر کنم ادعای درستی که می تونه در مورد سری زمانیش بکنه اینه که توی رزولوشنی که داره نگاه می کنه، مشاهده پذیرش با تقریب خوبی نویزه.
ممکنه همین پدیده توی یک رزولوشن دیگه اصلا نویز نباشه.
سوالو درست متوجه شدم؟؟
مرسی. بله تغییر پنجره میتونه نویز رو به داده تبدیل کنه و برعکس.
سوالم رو بازتعریف کنم :
در آزمایش های بیولوژی معمولا نمیشه تعداد آزمایش رو و یا زمان آزمایش رو به راحتی افزایش داد. در چنین حالت هایی چه جوری میشه ثابت کرد داده هایی که گرفتیم اطلاعات درستی را نشان میدهند و یا نویزشان بیشتر از اطلاعاتشان است؟
جوابشو نمیدونم الان چطوری میشه فهمید.
ولی در اینده وقتی با برداشت محدودیتهای مغز، بشر پیشرفت کنه احتمالا بشه.
فرض کن که این محدودیت زمان که اینجا اشاره شده به کمک ساعتهای دقیق اتمی برداشته بشه. یعنی یه طور عینک دیگه به چشم ادمها گذاشته بشه. یه ابزاری که درک مغز ما رو از چیزی که الان از زمان درک می کنیم عوض کنه
اینطوری به حرف بوهم میشه ایمان اورد که در کتاب خلاقیتش میاره :
بوهم نظم را نه کیفیتی صرفاً ذهنی، بلکه دارای ویژگی عینی میداند، چون بهزعم وی مبنای تعریف آن مشابهتها و تفاوتهای عینی هستند. نظم از دید وی یعنی وجود تفاوتهای مشابه و مشابهتهای متفاوت در یک بستر مشترک.
برای مثال یک خط را درنظر بگیرید. خط راست نوعی نظم اولیه و ابتدایی را نشان میدهد، چون اجزای آن طولهای کوچک و مشابهی هستند با امتداد یکسان، ولی در مکانهای مختلف.
حالا دایره را ملاحظه کنید. طولها انحنا دارند و امتدادها هم مختلف هستند، ولی زاویهٔ کمانها در مرکز برابر است. مارپیچ را که بررسی کنید، تفاوتها بیشتر میشوند و صفحات متعددی پدید میآیند که هر انحنا را از دیگری جدا میسازند.
بهاین ترتیب میتوان مثلا حرکت یک ذرهٔ براونی و آشوبناک را درنظر گرفت که کاملا تصادفی و نامنظم تصور میشود (مثل حرکت یک ذره غبار در هوا). اما این درواقع، حرکتی نامنظم نیست، بلکه مسیر ذره نظم پیچیدهای دارد و تفاوتهای مشابه در دینامیک آن بسیارند. نیروهای مشابه یا مختلف در جهتهای بسیار متفاوت بنا بر دینامیک واحد نیوتنی مسیر یک ذرهٔ براونی را تعیین میکنند. این مورد میشود نظم پیچیده.
از نظر بوهم مفهومی بهنام بینظمی وجود ندارد. آنچه ما بینظمی میخوانیم، نظمی با بینهایت مرتبهٔ مشابه و مختلف است. اما همین پدیدههای بهظاهر بینظم وقتی در قالب توصیف احتمالی و آماری ارائه میشوند، از پیچیدگی بهدر میآیند. یک ذره غبار که میانگین نیروهای وارد بر آن صفر است، میانگین مسیرش مثل یک خط صاف است! پس بینظمی مفهومی بنیادی نیست و در مراتبی به نظم ساده کاهش مییابد.
شاید اگه از فلسفه جدا بشیم، بشه یه کاری در مورد سئوال انجام داد. من فکر میکنم (تا اونجائی که با معادلات تصادفی و تحلیل داده ها) سرو کار داشتم، توی تفسیر دقیق ریاضی تعریف جامع برای اطلاعات نداریم ولی تعریف جامع برای نویز داریم که یه جنبه اون میشه دلتا بودن خودهمبستگی. توی داده های کم تجربی یه راه حل عمومی اینه که به رفتار سیستم با تغییر تعداد و بازه ها نگاه کنید. برای مثال اگه با تغییر این پارامترها رفتار بیشتر و بیشتر به سمت نویز میره میتونید بگید در حد دقت سیستم رفتار نویزیه.
یه نکته مهم هم اینه که از داده ها تجربی به اندازه خودشون میتونید انتظار داشته باشید و عموما با هیچ روشی نمی تونید اطلاعات را کامل به دست بیارید. برای مثال وقتی داده های زمانی در بازه محدودی دارید، تنها برای قسمت محدودی از تبدیل فوریه می تونید داده به دست بیارید (قضیه Nyquist).
ممنون. برای اینکه سوال مشخص تر بشه یه مورد از آزمایش های نوعی بیولوژی رو توصیف میکنم:
یه آزمایش رو تصور کنین که درش مکان تعدادی سلول، بگیم ۲۰۰ تا سلول، رو برای مدت محدودی، مثلا یه ساعت، در زمان دنبال کردیم. این سلولها، مثلا میتونن از نوع آمیبهای Dictyostelium discoideum باشن که در حضور گرادیان adenosine monophosphate حرکتشون از حالت پخشی خارج میشه و میخوایم مدلی برای توصیف دینامیک این موجودات ارائه بدیم.
محدودیت های آزمایش:
تمام سلولها در زمان مورد آزمایش در محدوده ی تصویربرداری قرار نمیگیرن. در نتیجه همهی سلول ها رو برای یه ساعت دنبال نکردیم. بلکه هر چی بازه ی زمانی طولانی تر باشه، از سلولهای کمتری داده داریم.
چنین سیستم هایی رو بهتره ارگودیک در نظر نگیریم (گرادیان غلظت داریم و خود غذا در حال پخش شدن در سیستم در زمان). افزایش تعداد آزمایش معمولا انتخاب راحتی نیست. مثلا برای گرفتن داده ی موثق از ۲۰۰ نمونه، اون هم برای زمان طولانی یه ساعت، شاید حداقل ۶-۹ ماه کار آزمایشی لازم باشه (حداقل).
این راه خوبیه، ولی برای مورد مشخص آزمایش بالا معادل ۲-۳ ماه آزمایش جدید هست. و با توجه به اینکه ابزار آزمایش تصویربرداری در دسترس خودمون نبود و در آزمایشگاهی در آلمان داده گیری انجام میشد(!) انتخاب مطلوب نبود.
حرفم اینه که در غیاب داده ی بیشتر، و به کمک چه پارامتری، میشه گفت که نمودارهایی که از داده ی تجربی به دست اومده، نویز هستن یا نه؟ و یا نمودار تئوری ای که بهشون فیت شده، برازش یه تابع مشخص به نویز بوده یا نه؟
لزومی نداره تعداد داده ها رو زیاد کنید. مثال: از 1/10 م داده های موجود استفاده کنید و به تدریج تعداد رو بالا ببرید. روندی که به دست میاد قاعدتا میتونه دیدگاه رو بهتون بده. زمان واهلش سیستم هم میتونه در مورد مثال شما خیلی کمک کنه.
هدف اگه مدلسازی باشه، من باشم از روشهای بازسازی دینامیک استفاده میکنم (reconstruction of dynamical systems) که بهتون اجازه میده از داده های زمانی دینامیک موثر رو بازسازی کنید.
من در حوزه بیولوژی هیچ دانشی ندارم، ولی طبق دانش خودم به سری صحبت ها میکنم شاید بدرد خورد شاید هم نه.
قطعا قبل از شروع آزمایش باید مشخص باشه که شما دنبال چه نوع محتوا یا داده ای هستید. هر تابع یا دنباله ای میتونه معنا داشته باشه، اگر مشخص باشه این تابع به چه هدفی در حال بررسی شدن هست. با صرف وجود یک داده و صرف هدف پیدا کردن یک معنا شاید خیلی کار سختی باشه که بتونید معنایی به اون داده نسبت بدید.
از طرف دیگه مدل تحلیل داده شما هم باید مشخص باشه. یک تابع برای دستیابی به هدفی مشخص بررسی میشه تا معنا داشته باشه و روش این بررسی هم باید مشخص باشه که خب مدل های تحلیل داده در هر تخصصی وجود دارند و هر روز در حال کاملتر شدن هستند.
از طرفی تقریبا تمام مدلهای تحلیل داده (حداقل در کار من و تا جایی که من ازشون استفاده کردم)، روشهایی برای آزمودن نتایج دارند که به عنوان مثال آیا رابطه معنا داره و اگر داره آیا این معنا قابل بسط هست یا خیر و …
از بررسی کردن حرکت اون سلول ها دنبال چه نوع مفهومی هستید؟ چی باعث شد که همچین چیزی رو دنبال کنید و قرار هست بر اساس چه استانداری این مفهوم رو پیدا کنید؟
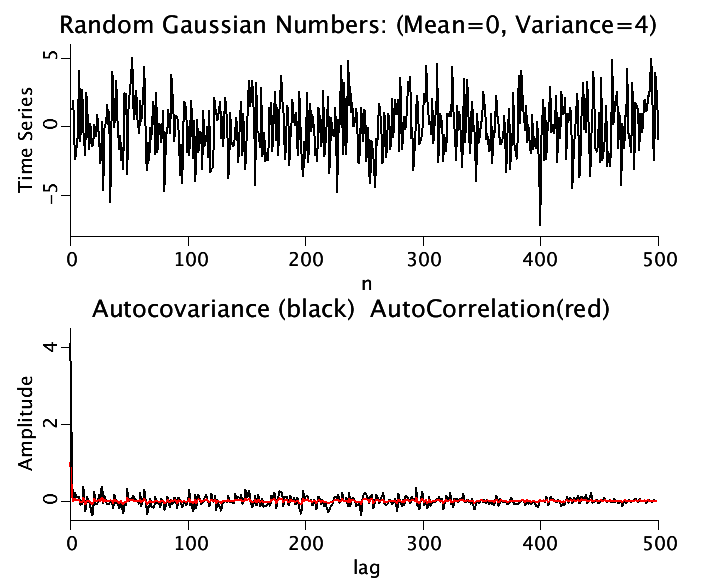
 :
: از بررسی کردن حرکت اون سلول ها دنبال چه نوع مفهومی هستید؟ چی باعث شد که همچین چیزی رو دنبال کنید و قرار هست بر اساس چه استانداری این مفهوم رو پیدا کنید؟
از بررسی کردن حرکت اون سلول ها دنبال چه نوع مفهومی هستید؟ چی باعث شد که همچین چیزی رو دنبال کنید و قرار هست بر اساس چه استانداری این مفهوم رو پیدا کنید؟